三维模型表示方法 相关论文总结
体素(Voxel Grids)
-
(2015 CVPR)3D ShapeNets: A Deep Representation for Volumetric Shapes (论文链接)
-
(2016 ECCV)Learning a predictable and generative vector representation for objects (论文链接)
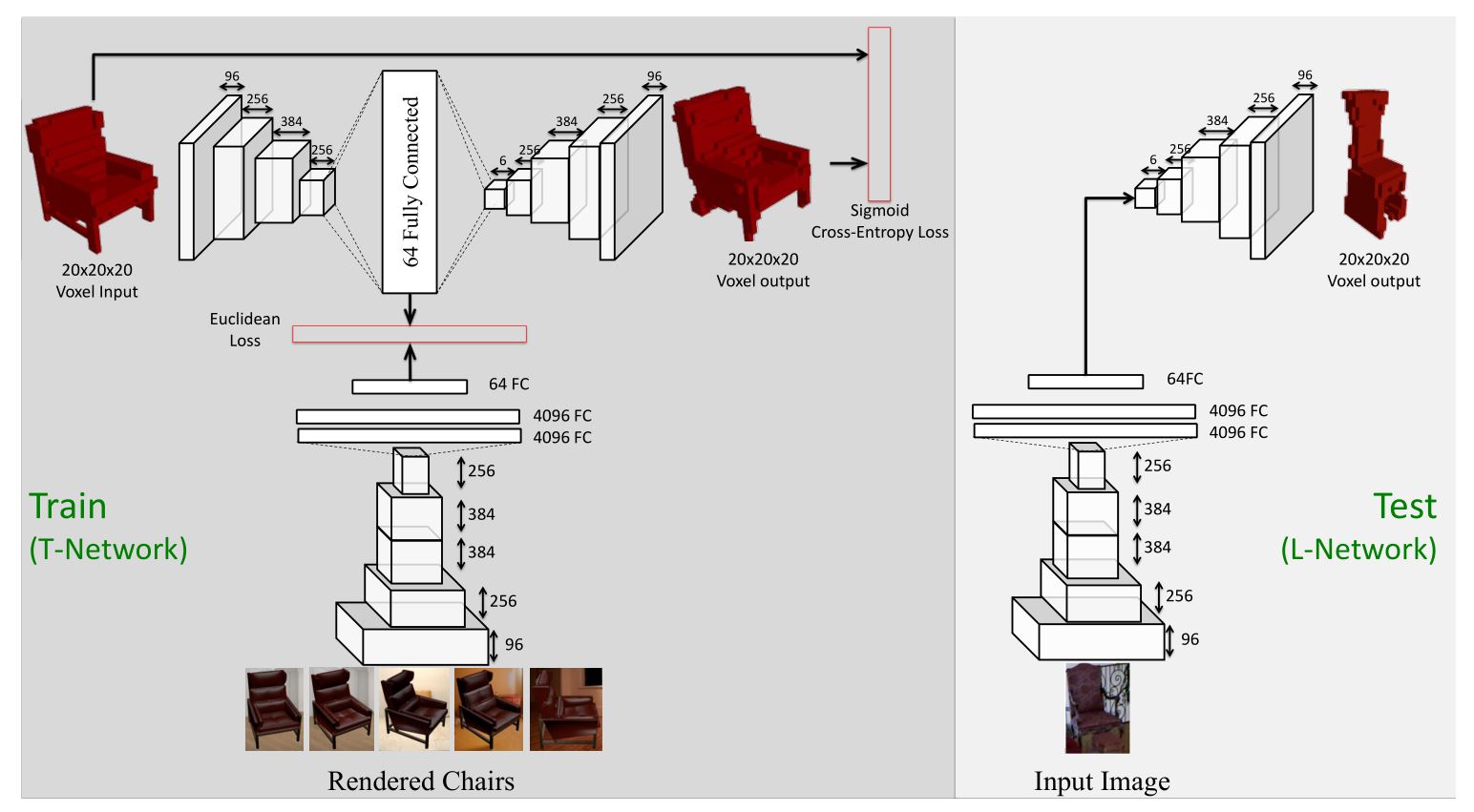
论文提出了TL-embedding Network,给出了一种对三维模型的表示,这一表示既能够用于三维模型的生成,也能够从二维图像中提取出来。网络结构分为两个部分,第一部分为自动编码器,得到三维模型的embeddings;第二部分为卷积神经网络,将二维图像提取特征信息映射到三维模型的embeddings上。但是在TL-embedding Network中,输入输出的体素模型大小为20*20*20,分辨率较低。
- (2016 ECCV)3D-R2N2: A unified approach for single and multi-view 3d object reconstruction (论文链接)
论文提出通过单张或者多张图片重新生成由体素表示的三维模型。神经网络将输入的图片看作一个序列,通过循环神经网络RNN对模型进行重建。
- (2017 SIGGRAPH)GRASS: Generative Recursive Autoencoders for Shape Sturctures (论文链接)
论文中将三维模型中的parts以层次结构的形式进行组织并对三维模型的structure进行编码,对于三维物体的结构,作者采用OBBs的形式进行表达;具体的几何细节利用体素表达。GRASS网络结构由三部分组成,第一部分为自编码器,其中的网络结构基于递归神经网络(RvNN)实现,达到将三维物体的不同part合并的目的;第二部分为GAN,训练这一部分使得网络能够生成新的三维模型;第三部分为自编码器,用于对模型几何结构的编码与表示。但是,采用RvNN的结构会存在很多不适合的层次结构,对这一部分的计算会占用大量的计算资源,因此GRASS很难处理高分辨率的模型。
- (2017 CVPR)OctNet: Learning Deep 3D Representations at High Resolutions (论文链接)
作者为八叉树的表示方法设计了新的卷积网络的计算方法,包括卷积操作,池化操作以及上池化操作。由于传统的八叉树在模型分辨率较高的时候树的深度较深,因此不利于对体素数据的读取,为解决这一问题,论文中限制了octree的深度,使得octree的深度不超过三层,被称为shallow octree,通过二进制的形式对体素的划分情况进行存储,之后,shallow octree按照位置关系被放入划定的网格中。通过这一方式表示的体素模型虽然压缩程度下降了,但是依然可以使用1个向量表示之前的个向量,且更利于神经网络的处理。
- (2017 ICCV)Octree generating networks: Efficient convolutional architectures for high-resolution 3D outputs (论文链接)
论文利用八叉树的结构递归地对三维模型进行生成,在递归过程中,网格中的八叉树节点被划分为“empty”,“filled”和“mixed”,被标记为“empty”与“filled”的节点划分完成,而标记为“mixed”的节点继续划分,且网络传递过程中,只将标记为“mixed”的节点特征信息传递到下一层。
- (2019 TOG)Global-to-Local Generative Model for 3D Shapes (论文链接)
论文通过GAN来生成三维模型,但考虑到GAN对于生成几何特征的表现并不好,作者通过GAN生成模型的大致结构以及每一个voxel对应的part的标签,再将这些信息按模型中的每一个part作为Part Refiner(PR)的输入,最终生成更精细的三维模型。其中,GAN的判别器被分为全局判别器与局部判别器,除此之外,作者提出了两种loss function保证GAN的训练效果。
- (2019 TOG)SAGNet: Sturcture-aware Generative Network for 3D-Shape Modeling (论文链接)
论文提出需要在对三维模型编码的过程中考虑到几何特征与整体结构的关系,SAGNet网络中通过循环神经网络GRU以及神经网络中的注意力机制将结构与几何特征之间的关系加入到其各自的训练中去。考虑到几何特征与模型结构之间的关系,能够很好地实现对榫卯结构的生成。
点云(Point Clouds)
- (2017 CVPR)PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (论文链接)
由于点云是三维点的无序集合,因此无法通过传统的神经网络对其处理,作者采用对称函数maxpooling的思想,保证了点集的排列不变性;点云中点的分布具有一定的空间关系,作者将局部特征与全局特征相串联来聚合信息;点云的特征不应随平移旋转等空间变换而发生改变,作者在网络中训练了变换矩阵将点云数据对齐。
- (2017 NIPS)PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space (论文链接)
PointNet难以捕获点云模型的局部特征,PointNet++网络主要由三部分构成:采样层(对点集采样作为局部区域的中心点)、组合层(找到中心点临近的点)、PointNet层(提取局部特征)。除此之外,由于点与数据在不同局部三维点的密度是不一致的,作者通过多分辨率组合的方法(MRG),提取的特征向量由两部分组成,第一部分由前一层的特征再通过特征提取得到,第二部分直接通过局部对应的原始点云通过特征提取得到,两部分对结构的影响由对应局部中的点的稀疏程度所决定。
- (2018 CVPR)FoldingNet: Point Cloud Auto-Encoder via Deep Grid Deformation (论文链接)
论文提出了一种基于折叠操作而建立的解码器用于将二维的网格点通过多次迭代操作最终折叠形成三维点云用于对三维模型的表示。模型中的编码器基于Graph,对点云中每个点的局部特征进行提取,最终得到512维的codeword,解码器将codeword复制后与二维网格点的位置相连,作为折叠操作的输入。
- (2019 TOG)StructureNet: Hierarchical Graph Networks for 3D Shape Generation (论文链接)
与GRASS方法相比,StructureNet采用图的形式描述模型的层次结构,首先通过模型的层次结构构建n叉树,再根据兄弟节点的关系(对称、连接等)连接对应的边。StructureNet采用基于图卷积的VAE对模型的Hierarchical Graph进行处理。
- (2019 ICCV)PU-GAN: a Point Cloud Upsampling Adversarial Network (论文链接)
这篇论文通过上采样的方法将稀疏、有噪音、不均匀的点云模型转变为密集、完整、均匀的点云模型。整体网络结构采用GAN,生成器的输入为原始的三维点集合、输出为上采样之后的三维点集,生成器可被分为三个模块:特征提取、特征扩展、以及点集生成;判别器相当于对上采样后的点集进行特征提取,再在最后连接全连接层实现对生成效果的判断。除此之外,作者提出了一种新的loss function以确保生成更均匀的三维点集。
三角网格(Mesh)
-
(2014 PAMI)Learning Spectral Descriptors for Deformable Shape Correspondence (论文链接)
-
(2015 ICCV)Geodesic Convolutional Neural Networks on Riemannian Manifolds (论文链接)
本文提出了定义在二维流形上的CNN模型,作者将三角网格中的每个点作为中心,提取对应的geometric patches,将其转换为极坐标的形式,再在patch上定义卷积操作,并对pathes离散化。卷积核同样被定义在极坐标上,为了消除歧义,在GCNN中,每个卷积核旋转次,抵消极坐标中角度的不同而带来的歧义。GCNN与定义在欧氏空间中的卷积网络类似。
- (2016 NIPS)Learing shape correspondence with anisotropic convolutional neural networks (论文链接)
GCNN中,卷积核为了消除歧义采用将极坐标旋转随机角度的方法。而在这篇论文中,作者提出了ACNN,通过各向异性的热量核函数(anisotropic heat kernels)代替之前的patch operator,实现对非欧氏空间中的卷积操作。
- (2018 CVPR)AtlasNet: A Papier-Mache Approach to Learning 3D Surface Generation (论文链接)
论文提出利用一系列的二维平面映射到三维模型的局部来描述整个目标三维模型,类似于一个二维流形的地图集。AtlasNet由多个MLP组成,每一个MLP的输入为三维模型的特征向量x以及从二维网格上采样的点的坐标,输出为该点在三维空间中的位置。在三维模型生成方面,作者提出了直接由单位平面转为三维模型、PSR方法、取样时改为从三维球体上采样等三种方式用于生成三维模型。
- (2018 ECCV)Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images (论文链接)
Pixel2Mesh从二维图像中提取特征信息将初始化的由Mesh表示的椭球体通过coarse-to-fine变形为目标三维模型。对于二维图像特征的提取采用CNN,提取后的特征与mesh中顶点的坐标与特征相结合,经过图卷积神经网络G-ResNet得到变形后的结构,每次变形后,引入上池化层,对mesh的分辨率进行扩展,以便生成更细节的模型。
- (2019 SIGGRAPH)SDM-NET: Deep Generative Network for Structured Deformable Mesh (论文链接)
论文提出了一种能够生成结构化可变形三角网格模型的网络结构,SDM-NET为两层VAE结构,第一层被称为PartVAE,用于对模型的每一部分几何特征的学习,将每一部分视为bounding box通过变形得到;第二层被称为Structured Part VAE(SP-VAE),同时学习各个部分间的结构以及每一部分的几何特征。
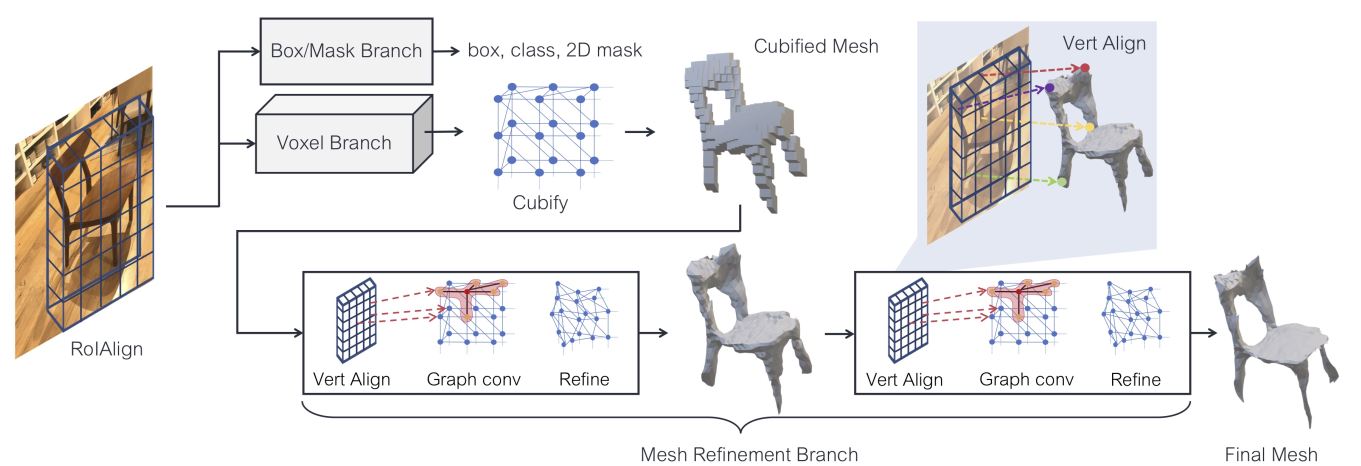
- (2019 CVPR) Mesh R-CNN (论文链接)
本文针对与真实世界中的图片往往具有多个物体,而且具有复杂的遮挡以及光线等的影响,提出了一种新的针对真实世界图像的三维模型生成方法。作者利用Mask R-CNN对于图片物体的提取能力,在这一基础上添加了生成三角网格的分支,首先生成粗体素模型,再在体素模型的基础上生成更加细化的三角网格模型,这一方法使得最终生成的模型具有了多样的拓扑结构。在训练神经网络的loss function上面,作者使用了倒角损失函数以及法向量损失函数,并再次基础上添加了一个正则化项,防止网络退化。
- (ICCV 2019)Pixel2Mesh++: Multi-View 3D Mesh Generation via Deformation (论文链接)
Point2Mesh++通过多张不同视角的图像生成模型,由粗糙到精细,作者提出MDN对模型中的每个点首先采样获取可能变形的位置,再给这些位置分配特征值,将其送入可微分的图卷积神经网络中进行训练,得到最终变形的位置。
Implicit Surfaces
- (2019 CVPR)Occupancy Networks: Learning 3D Reconstruction in Function Space (论文链接)
论文提出通过occupancy function来表示三维模型的方法,给定三维空间中的点,occupancy function判断该点是否位于三维模型内,论文提出用神经网络来拟合这一函数,函数二值的边界即表示三维模型的曲面。对于这一神经网络,输入为三维模型信息(图像、点云、mesh等)以及单个三维点的坐标,输出为0到1的实数,表示这一三维点被占用的概率。对于occupancy function ,输入为三维空间中的点, 输出为该点位于三维模型内部的概率,这一函数等价于求,输入为三维空间中的点以及三维模型的信息。
-
(2019 CVPR)Learning Implicit Fields for Generative Shape Modeling (论文链接)
-
(2019 CVPR)DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation (论文链接)
-
(2019 NeurIPS)DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction (论文链接)
DISN能够从二维的图像重建三维的模型,作者提出一种网络,首先根据二维图像学习相机参数,再根据这些参数将三维网格点映射到二维图像上,提取图像的全局特征以及映射点的局部特征,根据这些特征预测其SDF值,再根据SDF值重建三维模型。由于DISN采用了带符号距离函数而不是二值函数表示三维点相对于平面的位置,且在网络中添加了局部特征并修改了代价函数的权重,使得DISN与之前方法相比能够生成更精细的局部细节。
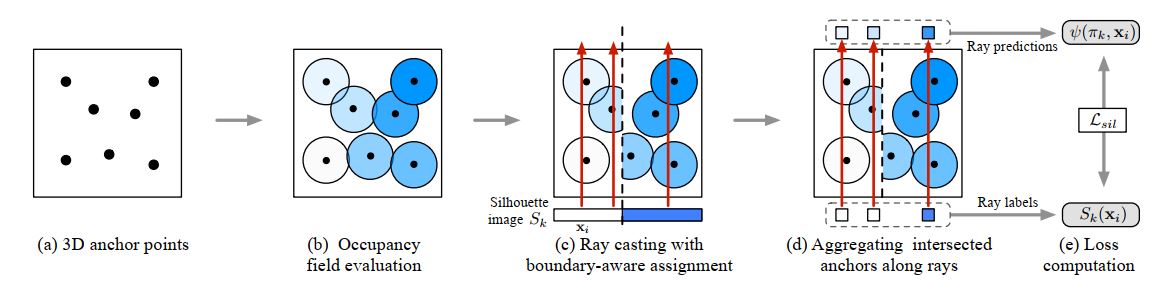
- (2019 NeurIPS)Learning to Infer Implicit Surfaces without 3D Supervision (论文链接)
论文提出了一种在没有三维模型信息的条件下,仅通过二维图像进行监督训练的网络模型。网络结构较为简单,分为两部分,第一部分对二维图像进行编码,输出为图像的特征向量,记为z,之后,z与三维空间中的一个点p作为输入,送入网络的第二部分,第二部分输出为该点位于模型内部的概率。论文主要提出了通过ray probing的方法对三维空间中采样的锚点与图片对应的像素点进行比较,给出了一种新的对三维模型轮廓优化的代价函数。除此之外,论文提出了一种新的代价函数,用于对模型表面几何特征的优化。
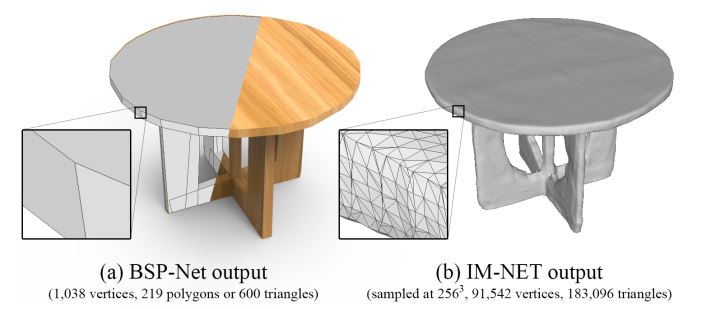
- (3029 arXiv)BSP-Net: Generating Compact Meshes via Binary Space Partitioning (论文链接)
论文提出通过一系列凸多面体的组合来表示三维模型,组合方式通过BSP-tree来表示,BSP-tree分为三层:第一层表示为三维平面,将三维空间分割为内部和外部两部分;第二层为凸多面体,通过三维平面的组合得到封闭的凸多面体集合;第三层为组合层,在凸多面体集合中进行选择,得到最终的三维模型。不同于其他隐式曲面的方式,需要进行isosurface处理来提取三维曲面,BSP-Net方法能够直接通过多面体的组合得到三维模型,且能够表示三维模型中的sharp geometry feature。
- (2019 ICCV)Learning Shape Templates with Structured Implicit Functions (论文链接)
本文提出SIF(Structured Implicit Functions)作为一种对三维模型曲面的隐式表示方法。作者将三维模型看作由多个shape elements组合而来,每个shape elements通过一个高斯函数来表示,这些函数相加来表示整个三维模型曲面,函数的参数通过神经网络进行学习。
- (2019 arXiv)Deep Structured Implicit Functions (论文链接)
作者提出DSIF,在SIF的基础上进行了优化,每个shape element通过SIF粗略表示,再与DIF相乘对模型细节的表示进行优化。DIF(Deep Implicit Functions)通过神经网络Occupancy Network进行优化。
- (2019 arXiv)NASA: Neural Articulated Shape Approximation(论文链接)
作者提出了三种不同的结构,利用有关节三维模型的变形信息,对三维模型进行表示。unstructured model(U)将模型看作一个整体,直接利用DeepSDF等方法对网络进行训练;piecewise non-rigid model(R)将模型看作由一组不可变形的元素组成,对每个元素利用变形信息分别进行训练,再将其组合;piecewise deformable model(D)将模型看作由一组可变形的元素组成,再对每个元素进行训练。
Other structured representation
- (2017 ICCV)3D-PRNN: Generating Shape Primitives with Recurrent Neural Networks (论文链接)
将三维模型粗略地看作由多个立方体组成,这些立方体被称为primitives,通过循环神经网络RNN按序列对primitives进行生成,得到最终地三维模型。