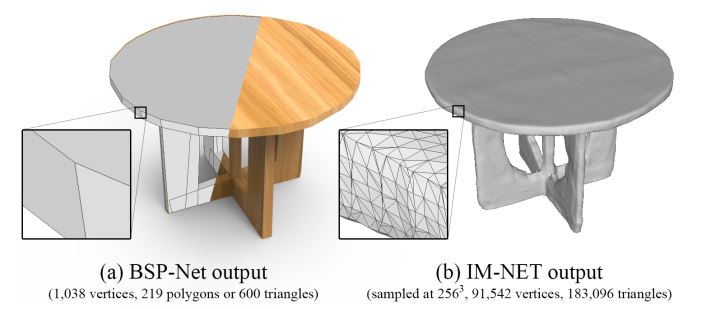
BSP-Net
参考论文
BSP-Net: Generating Compact Meshes via Binary Space Partitioning
论文链接
Introduction
对于通过implicit function,利用等值曲面提取生成mesh的方法具有计算代价高,不能生成尖锐几何特征的缺点。利用BSP不断地将空间递归分割为凸面体的集合,论文提出了BSP-Net,通过对凸多面体的分解来表示三维模型。对于三维模型的重建则利用BSP-Net建立的BSP Tree中凸多面体的集合。利用凸多面体来表示三维模型,具有占用空间小(compact)以及能够表示尖锐几何特征的特点,且不受拓扑结构的限制。除此之外,BSP-Net是无监督的。
Background
Bianry Space Partitioning(BSP-Tree)
参考链接
概念
BSP树是一种数据的组合形式,构建的过程从某种类型的数据开始,将其分成两个部分,再将这两个部分继续分割,直到得到最小的单元。
BSP Tree in Computer Graphics
BSP Tree起初用于加快渲染器的渲染速度:
当渲染器去渲染一 ...
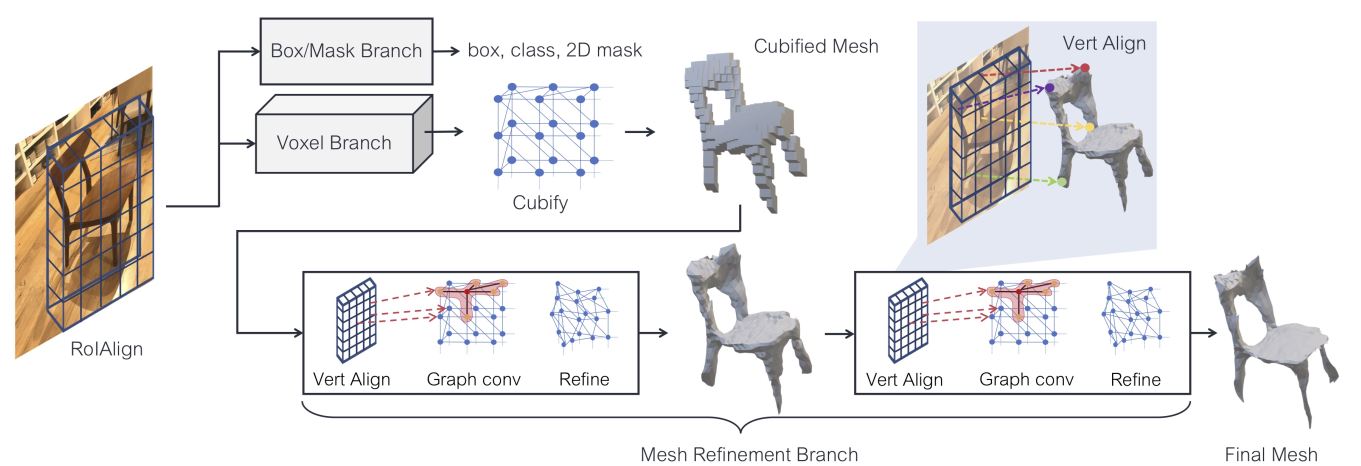
CVPR 2019 Mesh R-CNN
参考论文
Mesh R-CNN
论文链接
Introduction
给定一张真实图片,论文提出了一种新的模型用于生成检测出的每一个物体的三角网格模型。这一模型被命名为Mesh R-CNN,是在Mask R-CNN的基础上添加了一个网格模型的预测分支用于生成具有各类拓扑结构的网格模型。论文提出,首先通过检测出的物体,粗略的生成这一物体的体素模型,之后再将体素模型转换为三角网格模型,最后通过图卷积网络生成更加真实的三维网格模型。之前的模型大多数专注于对类似ShapeNet而言,对单个物体进行渲染与生成,但是真实图片中的情况要更加复杂,图片内会有多个物体、物体间会有一些遮挡关系以及会有不同的光照条件的影响,这篇论文是对解决这一类问题的一种尝试。
对于三角网格模型的重建大部分方法采用通过一个template变形的方式生成目标三维模型,因此,生成的三维模型会与原始的模板具有相同的拓扑结构,这一方式在一定程度上限制了三维网格模型的生成质量。为解决这一问题,作者首先根据图像生成一个粗略的体素模型,再根据体素模型生成更加精细的三角网格模型。
Method
模型的整体结构如上图所示,为Mask R ...

CVPR2018 AtlasNet
参考论文
AtlasNet: A Papier-Mache Approach to Learning 3D Surface Generation
论文链接
Introduction
曲面的形式定义为局部类似于欧几里得平面的拓扑空间,因此,作者在这篇论文中提出去通过一系列的平面映射到三维模型曲面的局部来估计整个目标曲面。这一工作介于利用少量的、固定的参数模块来表达一个三维物体以及利用大量无结构的点集来表示一个三维物体之间。也可以被理解为对曲面学习一种分解的表达方式,其中曲面上的点被编码模型结构的向量以及编码点的位置的向量所表示。通过将多个平面映射到三维物体上,理论上可以得到任意分辨率的三维模型,并且可以为生成的模型添加纹理映射。
如上图所示,对于所有三维生成模型的方法而言,大致可被抽象为将隐含的模型表示作为输入,输出为生成的三维点的集合。图(a)即为最基本的方法,论文作者在此基础上在输入端添加了从一片平面上通过均匀取样的一个二维点,并利用这个二维点生成曲面上的一个点。因此,生成的模型就可以表示为一片连续的曲面。利用这一方法,网络也可以用来生成任意分辨率的三维模型。图(b)描述了上述方 ...
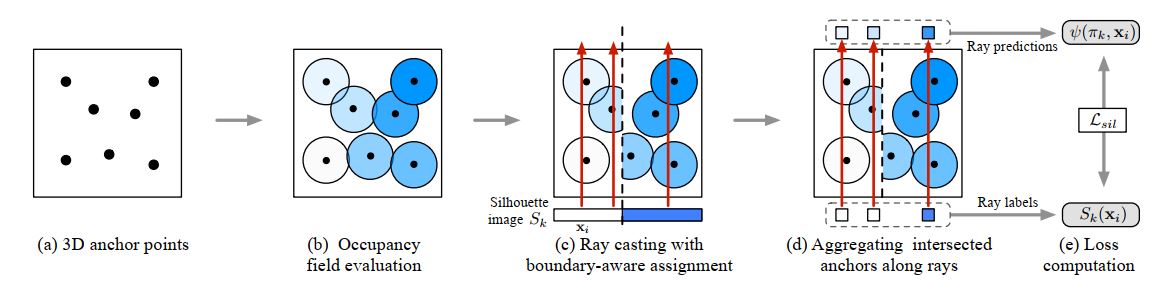
NeurIPS2019 Learning of Implicit Surfaces without 3D supervision
参考论文
Learning to Infer Implicit Surfaces without 3D Supervision
论文链接
Introduction
目前来说,我们拥有海量的二维图片,而三维模型的dataset相对来说较少,因此人们希望能够从二维图片中直接生成三维模型。对于主流的几种三维模型表示方法来说,点云与体素受限于模型的分辨率,三角网格难以有效地处理不同的拓扑结构。而Implicit Surfaces能够解决这些问题,但也存在难以构建三维与二维的联系、难以保证局部光滑的问题。这篇论文中,作者提出了ray-based field probing technique以及一个通用的geometric regularizer来解决上述问题,提出了一种仅通过二维图像来生成三维模型的框架。
对于显式的三维模型表示方法而言,能够很容易地将三维模型映射到二维图像上,反过来也很容易获得梯度流用于三维模型生成的监督学习。但是对于Implicit Surface而言,不能直接将其映射到二维平面上,而是采用ray sampling的方法,通过取样进行计算,但采用这种方法也会带来较大的计算 ...
三维模型表示方法 相关论文总结
体素(Voxel Grids)
(2015 CVPR)3D ShapeNets: A Deep Representation for Volumetric Shapes (论文链接)
(2016 ECCV)Learning a predictable and generative vector representation for objects (论文链接)
论文提出了TL-embedding Network,给出了一种对三维模型的表示,这一表示既能够用于三维模型的生成,也能够从二维图像中提取出来。网络结构分为两个部分,第一部分为自动编码器,得到三维模型的embeddings;第二部分为卷积神经网络,将二维图像提取特征信息映射到三维模型的embeddings上。但是在TL-embedding Network中,输入输出的体素模型大小为20*20*20,分辨率较低。
(2016 ECCV)3D-R2N2: A unified approach for single and multi-view 3d object reconstruction (论文链接)
论文提出通过 ...
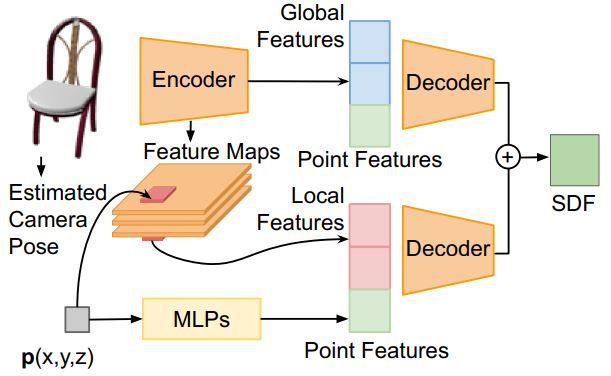
NeurIPS2019 DISN
参考论文
DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction
论文链接
Introduction
本文提出了一种新的从二维图片中重建三维模型的方法,通过预测三维空间中的符号距离来从二维图片中生成具有更高细节质量的三维网格模型。与其他方法只能够重建物体的整体结构相比, DISN重建出的模型具有更好的细节,例如模型中的孔以及模型中比较细的结构,重建效果如下图所示:
在这篇论文中,为解决其他三维表示方法分辨率不高,拓扑结构不能改变,难以描述物体的具体细节等问题,作者选择学习一种隐含的三维曲面的表示方法,被称为Signed Distance Functions(SDF)。SDF把从三维空间中取样得到的点编码为到物体表面上带符号的距离。因此,只需要给定一个带符号距离值的集合,就能够从其中提取到对应的三维模型。
为解决生成模型细节的问题,作者引入了局部特征提取模块,首先,模型将从输入的图像中提取视角的参数,之后利用这些信息将每个查询的点投影到输入的图像上来识别相应的local pa ...
ICCV2019 C3DPO
参考论文
C3DPO: Canonical 3D Pose Networks for Non-Rigid Sturcture From Motion
论文链接
Introduction
C3DPO用于从2D的关键点的标注中提取并建立对于可变形物体的三维模型。与其他同类方法不同的是,C3DPO的训练不需要三维的信息。
C3DPO通过神经网络从二维图像中的关键点分解得到模型的视角、变形等信息,的主要贡献在于:(1)在重建三维标准模型以及视角的过程中仅使用了单一图片中的二维关键点。(2)使用一种新的自监督的限制将三维的形状以及二维的视角分离。(3)可以处理在观察过程中被遮挡的部分。(4)在多种不同类的物体上都有很好的表现。
Overview
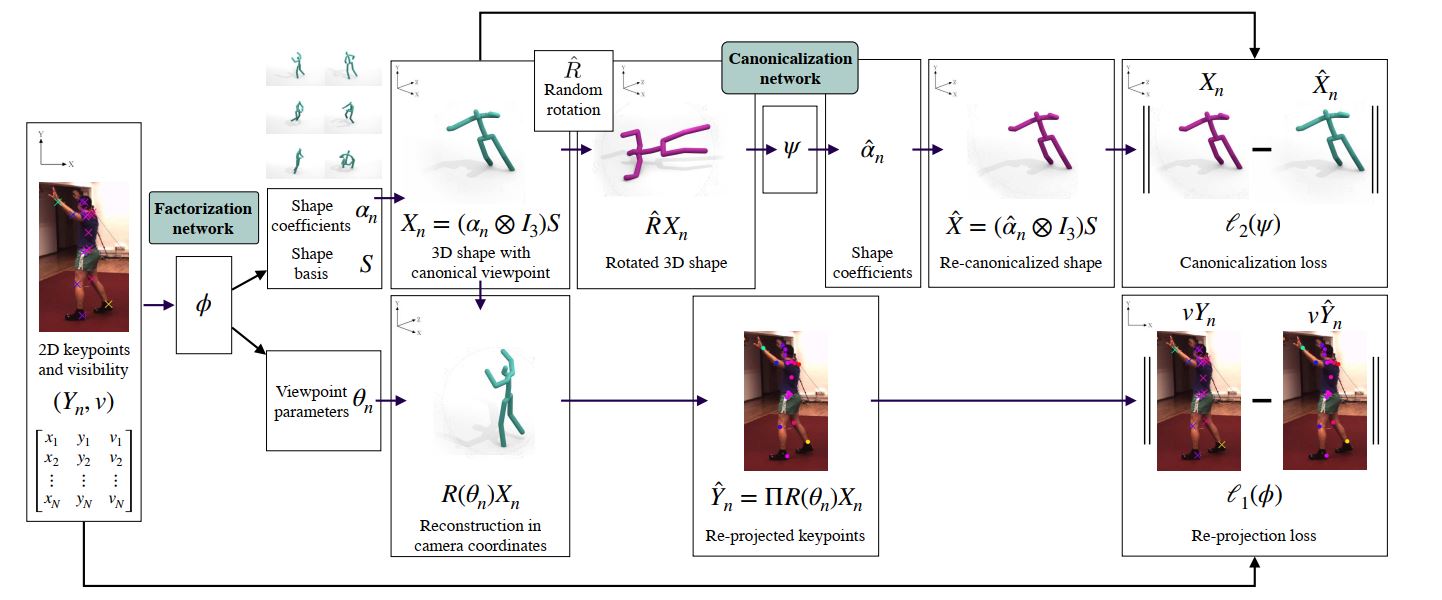
C3DPO的整体结构如下图所示:
Method
Sturcture from motion(SFM)
SFM的输入为元组yn=(yn1,…,ynK)∈R2×Ky_n = (y_{n1}, \dots, y_{nK}) \in \mathbb{R}^{2 \times K}yn=(yn1,…,ynK)∈R2×K表示二维的关键点,其中yny_nyn ...
ICCV2019 PU-GAN
参考论文
PU-GAN: a Point Cloud Upsampling Adversarial Network
论文链接
Introductin
通过扫描仪等设备所获得的三维模型的点云通常是稀疏的、有噪音的、不均匀的,因此,在对这一类的点云数据进行进一步处理之前, 需要通过一些方式对其进行修改,生成密集、完整、均匀的点云集合。在这片论文中,作者提出了一种新型的点云upsampling框架,并命名为PU-GAN。
Method
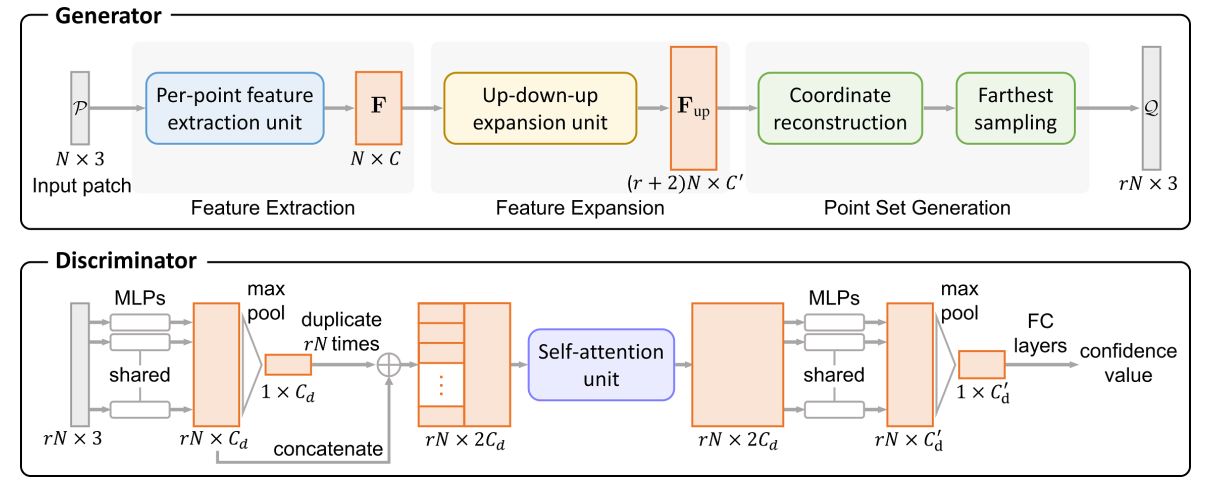
Overview
给定一个无序的点击P={pi}i=1N\mathcal{P} = \{p_i\}^N_{i=1}P={pi}i=1N,期望生成一个更加密集的点集Q={qi}i=1rN\mathcal{Q} = \{q_i\}^{rN}_{i=1}Q={qi}i=1rN,其中r被称为上采样率。对于生成的点击Q,需要满足两个条件:
输出Q与输入P应该对一个目标物体描述了同样的集合特征,因此在集合Q中的点应该分布并且覆盖在目标物体的表面。
即使输入P中的点是稀疏并且不均匀的,输出Q上的点也应该均匀分布在目标物体的表面
PU-GAN的网络结构如 ...