三维模型表示:TL-embedding Network
object representation
一个三维模型的表示应符合两个标准:
- 在三维空间中是可生成的(We should be able to reconstruct objects in 3D from it.),即需要保证物体可以通过这种表示被重构出来。
- 在二维空间中是可预测的(We should be able to easily infer this representation from images.),即需要能够从二维图像中提取出这种对三维模型的表示。
参考论文
Learning a predictable and generative vector representation for objects
Introduction
之前的工作主要关注上述两个标准的其中一个,很少有工作将两者结合起来,这篇论文提出了一种将三维模型和二维图像结合的训练方法,作者将其称为TL-embedding network。它将三维模型与二维图像同时映射到latent space中。通过这一模型,我们既可以从二维模型中学习到三维物体的表示,也可以通过表示构建出物体的三维模型。
在TL-embedding network中,主要有两部分组成:第一部分是一个自动编码器,负责将三维的体素网格映射到64维的latent space中,并且将其解码到体素网格;第二部分是一个卷积神经网络,将二维的RGB图像映射到64维的latent space中。
TL-embedding Network
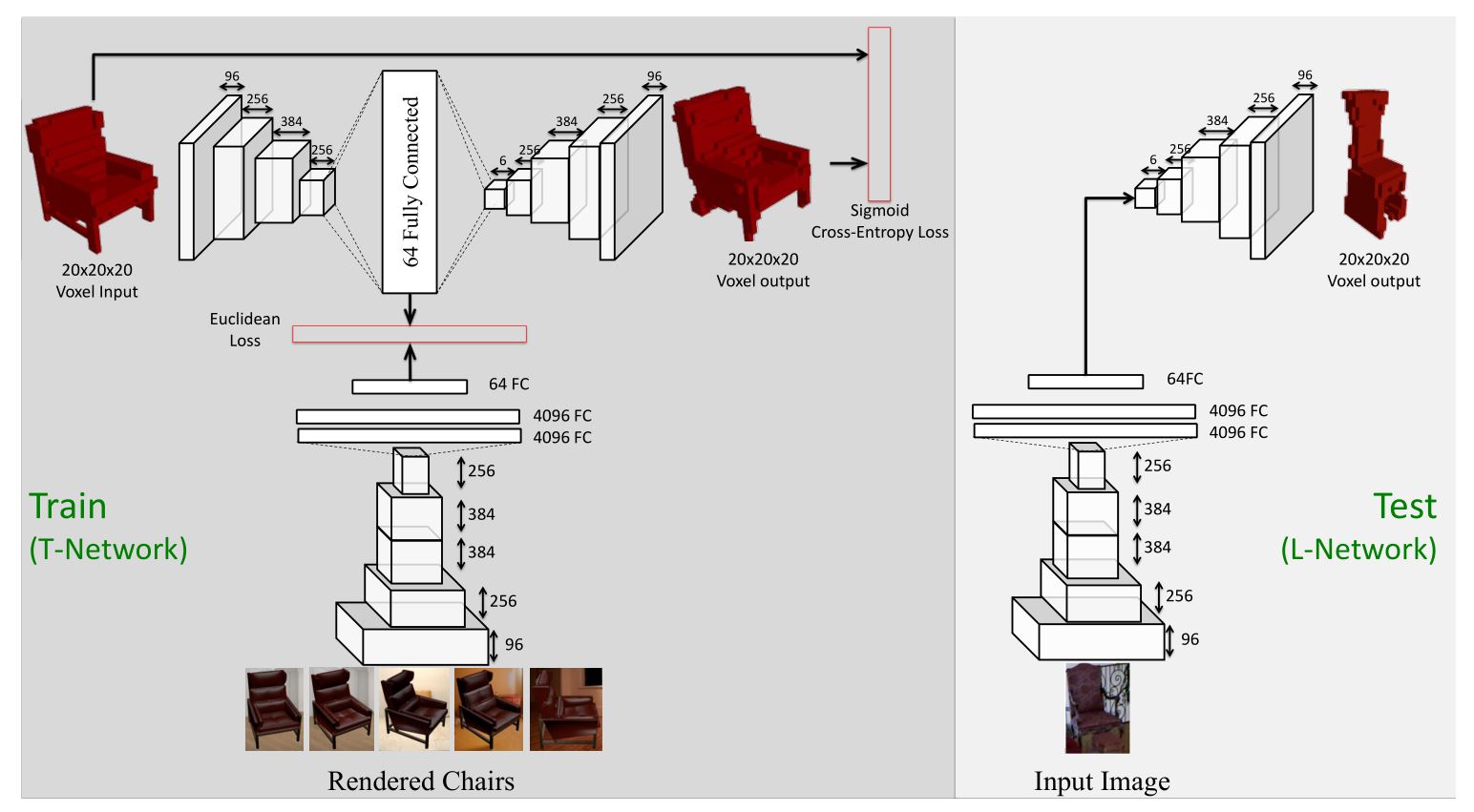
TL-embedding Network的结构如上图所示。用于训练的神经网络被称为T-embedding Network,这一网络有两种不同的输入,分别是二维的RGB图像以及三维的体素模型,最终输出为三维的体素模型,网络的代价函数设置为体素重建的损失函数以及两种64维向量表示的欧式距离的结合。用于测试的神经网络被称为L-embedding Network,在测试网络中,输入为二维的RGB图像,卷积网络将从二维图像中提取出三维模型的信息作为representation,之后的decoder将预测最终的三维体素模型。
Autoencoder Network Architecture
自编码器使用20*20*20的voxel grid representation作为输入,编码器包含了四层卷积层,之后连接了一层全连接层用于生成中间向量;解码器通过五层deconvolutional layers将向量映射到的voxel grids。
自编码器采用交叉熵代价函数:
其中,是指原始体素模型中第n个体素是否被填充的概率(1或0),是指解码器生成的变量经过sigmod函数得到的预测概率,。
Mapping 2D Image to Embedding Space(ConvNet Architecture)
T-Network中的下半部分将二维RGB图像映射到64维的向量空间中,损失函数采用欧式距离作为损失函数。