GCNN 图卷积网络
传统卷积神经网络CNN
卷积在通常的形式中,是对两个实变函数的一种数学运算。在卷积网络的术语中,卷积的第一个参数通常叫做输入,第二个参数叫做核函数,输出有时被称为特征映射。在传统的卷积神经网络中,由于卷积操作具有稀疏交互、参数共享、等变表示的特征而被广泛应用。
从本质上讲,CNN中卷积本质上是利用一个共享参数的过滤器,通过计算中心像素点以及相邻像素点的加权来实现对输入数据特征的提取。
图卷积网络GCNN
卷积神经网络在计算机视觉以及自然语言处理方面取得了巨大的成功,但是卷积神经网络的输入必须是Euclidean domain的数据,即要求输入数据有规则的空间结构。但是,依然有很多数据并不具备规则的空间结构,这些数据被称为Non Euclidean data。
Graph
Graph Convolution Network中的Graph是指图论中的用顶点和边建立相关对应关系的拓扑图,具有两个基本的特征:
每个节点都有自己的特征信息
图中的每个节点还具有结构信息
图卷积算法
图卷积算子:
hil+1=σ(∑j∈Ni1cijhjlwRjl)h^{l+1}_i = \sigma( ...
ICCV2019 Triplet-Aware Scene Graph Embeddings
参考论文
Triplet-Aware Scene Graph Embeddings
论文链接
Introduction
场景图(Scene graphs)作为一种结构数据用于描述两两物体之间的语义关系。在Scene graph中,每个节点代表一个物体,每一条边代表两个物体之间的关系,用一个三元组<subject, predicate, object>来表示。例如:<cat, on, road>,<dog, left of, person>。对于场景图的解释如下图所示(D.Xu, Y.Zhu, C.Choy and L.Fei-Fei. Scene graph generation by iterative message passing. In Computer Vision and Pattern Recongnition, 2017):
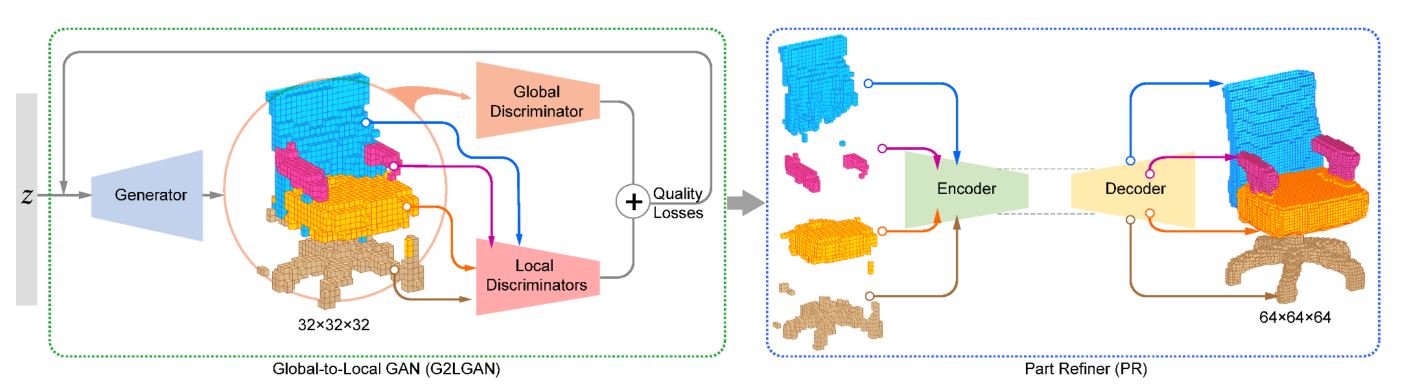
TOG2019 Global-to-Local Generative Model
参考论文
Global-to-Local Generative Model for 3D Shapes
论文链接
Introduction
对抗生成网络(GAN)在非常多的领域中被广泛应用,并取得了非常好的效果,通常来说,GAN能够很好地从类的分布中取样,但是对细节的生成不够好。而对于3D Shape来说,GAN虽然能够很好地生成三维模型的结构,但是很难生成好的几何细节。
在这篇论文中,作者提出了一种Global to Local(G2L)的生成模型用于生成3D Shape,这一模型首先通过对抗生成网络去生成全局的结构以及局部的标签,之后,全局的判别器用于区分真实与生成的3D Shape,而局部的判别器用于区分局部的每一部分,最后,再通过条件自编码器去提高局部部分的生成质量。同时,作者通过进一步优化额外的两类loss去保证模型生成的效果,第一,尽量保证每一个部分中体素的标签尽可能统一,第二,尽量保证生成模型的表面是平滑的。
The Overview of G2L
Global-to-Local Generative Model的结构图如下所示:
这一生成模型由两部分组成,包括左半部 ...
CVPR2018 FoldingNet
参考论文
FoldingNet: Point Cloud Auto-Encoder via Deep Grid Deformation
论文链接
Introduction
三维点云集合是一种不规则,无序的数据结构,很难通过二维神经网络的方法对其进行处理,之前对于点云的处理通常是将其体素化后再进行处理。
在本文中,作者将三维点云看作一个物体表面经过采样之后的结果,因此,一个三维的点云可以用二维网格点通过fold的操作(包括裁剪、折叠以及拉伸等)来获得。本文所提出的网络中decoder的部分,就模拟了折叠这一过程,从论文的实验结果就可以看到,只要经过两次折叠,就能够得到较好的生成模型,如下图所示:
总结来看,这篇文章提出了一种新的端到端的自动编码器,能够直接处理无序的三维点云集合;提出了一种新的decoder的思路,通过折叠的方式重建三维模型;通过FoldingNet生成的codeword同其他方法相比,有着更好地分类效果。
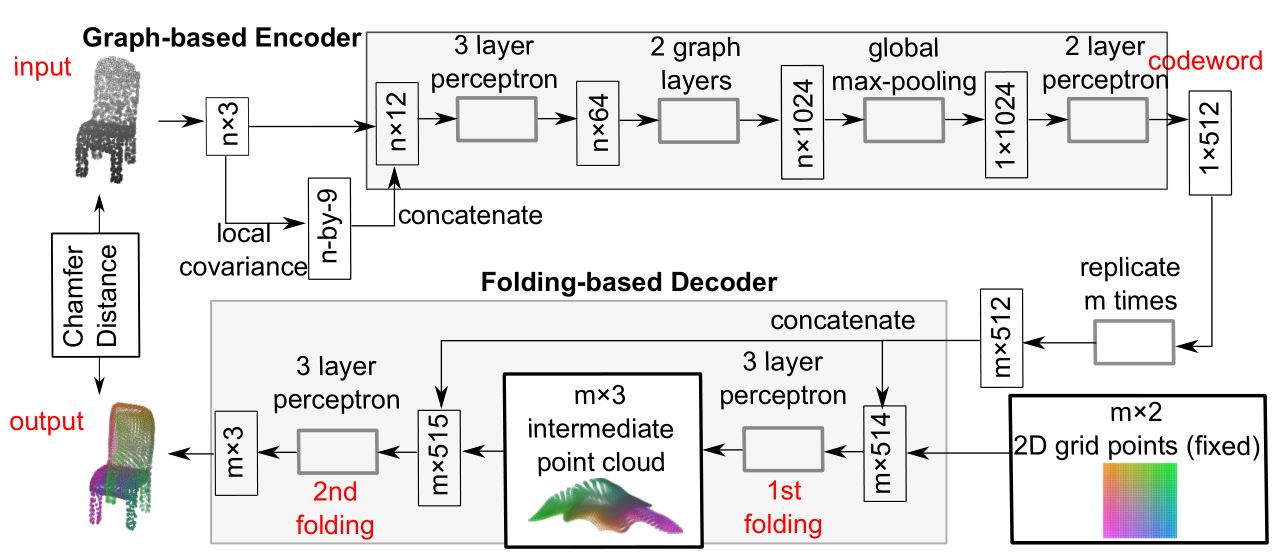
The overview of FoldingNet
FoldingNet的网络结构如下图所示:
Graph-based Encoder Architectur ...
SIGGRAPH2017 GRASS
参考论文
GRASS: Generative Recursive Autoencoders for Shape Sturctures
Introduction
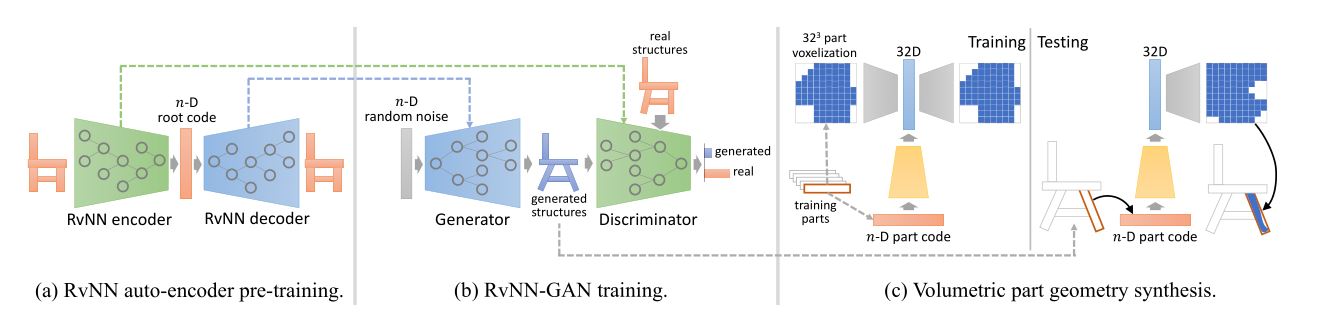
三维模型可以通过模型中各个部分的层次结构有效地表示出来,这种层次结构能够反映出模型内部的关系,例如连接关系以及对称关系。本文希望通过一个生成网络,去表示一类物体的模型结构(shape structure)。
对于三维模型的生成,应该同时考虑模型的结构以及几何细节,但是模型的结构是离散的,几何细节是连续的,因此需要设计一种网络将这两个部分结合起来。除此之外,对于一个类别的模型,例如椅子,它们之间的结构也是不相同的,如果将模型的结构用图进行表示,则需要网络能够处理不同结构以及规模的图数据。
对于一个模型的结构,包含对称以及连接的信息,这种层次关系通过图来表示,不论图的结构变化如何,都可以通过一种算法递归地将图的节点汇聚到其父节点并最终汇聚到根节点,通过这种方法,shape structure就可以通过一个固定长度的向量表示出来。论文中学习了一种神经网络,能够将模型的层次结构通过encoder编码成一个根节点编码并通过decoder ...
三维模型表示:TL-embedding Network
object representation
一个三维模型的表示应符合两个标准:
在三维空间中是可生成的(We should be able to reconstruct objects in 3D from it.),即需要保证物体可以通过这种表示被重构出来。
在二维空间中是可预测的(We should be able to easily infer this representation from images.),即需要能够从二维图像中提取出这种对三维模型的表示。
参考论文
Learning a predictable and generative vector representation for objects
Introduction
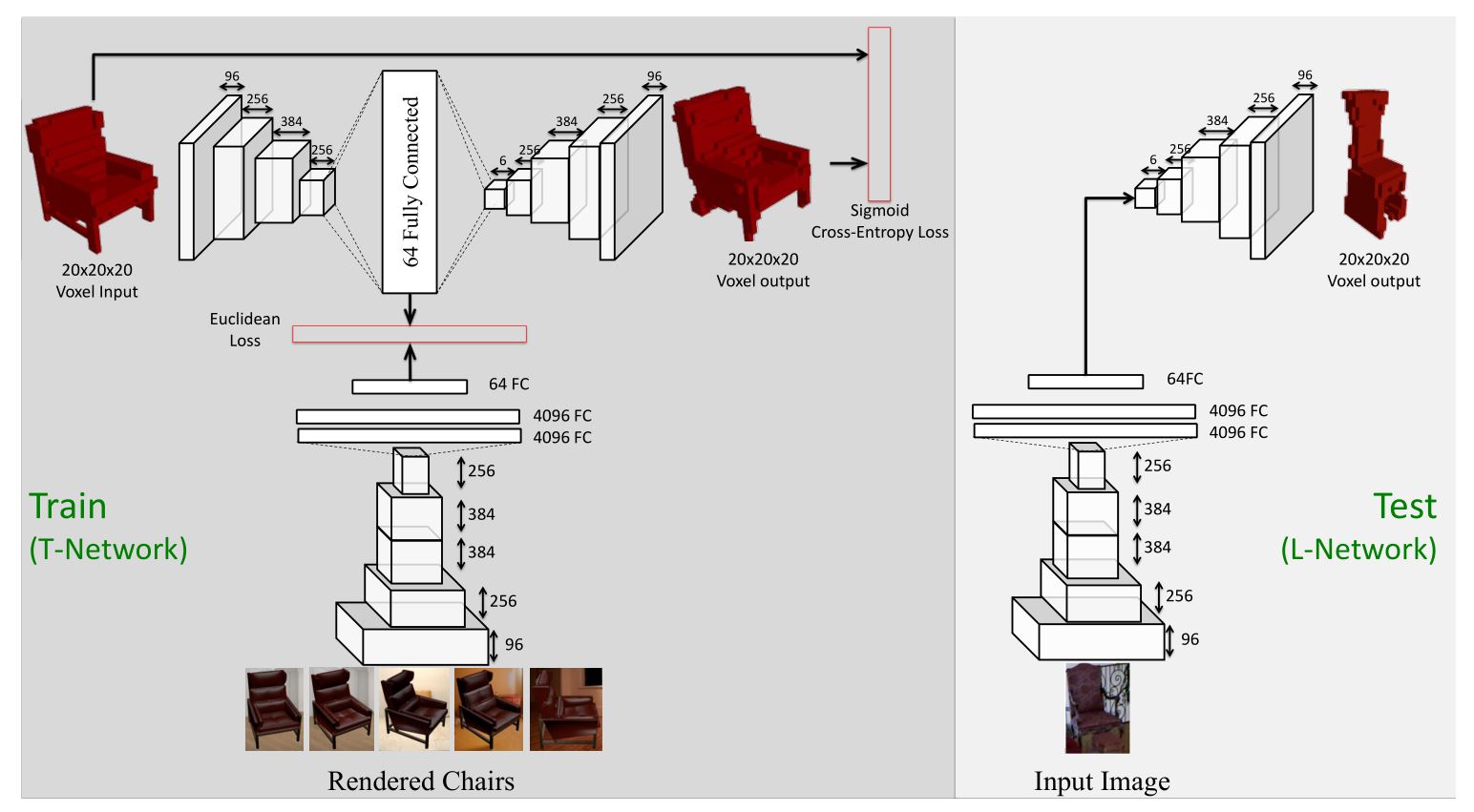
之前的工作主要关注上述两个标准的其中一个,很少有工作将两者结合起来,这篇论文提出了一种将三维模型和二维图像结合的训练方法,作者将其称为TL-embedding network。它将三维模型与二维图像同时映射到latent space中。通过这一模型,我们既可以从二维模型中学习到三维物体的表示,也可以通过表示构建出物体的三维模型。
在TL- ...

Hexo博客以及Melody主题
Welcome to Hexo! This is my very first post.
Hexo博客
常用hexo指令
123456hexo new "postName" #新建文章hexo new page "pageName" #新建页面hexo generate #生成静态页面至public目录hexo deploy #部署到GitHubhexo help #查看帮助hexo version #查看Hexo版本
More info: Writing Server Generating Deployment
写博客
定位到hexo根目录下,执行命令:
1hexo new 'my-blog-name'
hexo就会在_post文件夹下生成对应的markdown文件。
Melody主题
Melody主题的搭建与使用参考官方文档